Analysis Scripts
Key Take Away :
Defining Script for Analysis automation
Using the right combination of packages fromt he R statistical language, it is possible to integrate all necessary data analysis steps into scripts:
Data management (clean, recode, merge, reshape)
Data analysis (test, regression, multivariate analysis, etc…)
Data visualisation (plot, map, graph…)
Writing up results (report and presentation generation)
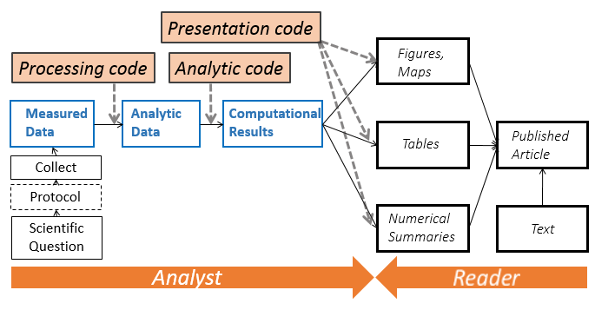
This allow for reproducible data analysis workflow
Categorical variables having several code options:
- In the data cleaning process, make sure that the codes are the same as those on the standard questionnaire. E.g. vitamin A should be coded 1-3 in the questionnaire but code ‘4’ may appear in the database. This code ‘4’ needs to be excluded from analysis and not included in the denominator as it was a mistake in data recording on the field.
Code ‘8 or ‘98’ for ‘don’t know’:
- Make sure to exclude codes ‘8’, ‘98’ or ‘998’ for ‘don’t know’ from the analysis. This should not be part of the denominator in the calculation of indicators (e.g. diarrhoea, IYCF, ANC enrolment).
Code ‘6’ or ‘96’ for ‘other’:
- Make sure to include codes ‘6’ or ‘96’ for ‘other’ in the analysis. This should be part of the denominator in the calculation of indicators as it represents one response option (e.g. safe disposal of U3 stool, reason for not having a ration card, source of water).
Recoding with the ‘if’ command in Epi Info software:
- Do not forget to take into account missing values when using the ‘if’ command. This applies to many different variables. Whenever feasible, it is much better to use the ‘recode’ command instead of the ‘if’ command for this specific reason.
Confidence intervals:
- Different software often calculate confidence intervals as being negative and hence below zero or above 100. Negative confidence intervals or CI above 100 are meaningless. In the report, always round negative confidence intervals to ‘0’ and round those above 100 to ‘100’.
Rounding decimal points:
- Make sure to round properly decimal points according to basic rules:
- When decimal is between 1-4, round down.
- When decimal is between 5-9, round up.
Decimal points in the results:
- When the results is a whole number e.g. 30%, make sure to always write 30.0% with the ‘.0’ in the decimal place in the report. This ensures that the decimal point was not forgotten and is actually equal to zero.
Missing data or consent not provided:
- Data should be excluded from all analysis and should not be accounted for in the denominator.
Always clean the data first before going into analysis:
- Frequencies and means should be run on categorical and continuous variables, respectively.
- Missing data should be looked at and a record of them should be kept.
Age variable:
- When selecting age or creating an age variable category in Epi info software from the ‘months’ variable generated by ENA, don’t forget the ‘.99’ otherwise some children with an exact birth date may be excluded from the analysis. E.g. 6-23.99 (and not 6-23 or 6-23.9).
Reproducible Analysis
Always save newly generated variables into a new data file named following a naming convention to be respected by all involved in the survey data analysis.